
Revolutionizing Duplicate Question Detection: A Deep Learning Approach for Stack Overflow
Revolutionizing Duplicate Question Detection with Deep Learning on Stack Overflow
Duplicate questions can flood community-driven forums like Stack Overflow, reducing user efficiency and response accuracy. In a recent study published in IgMin Research, Muhammad Faseeh and Harun Jamil proposed an advanced deep learning approach to streamline the process of identifying duplicate questions. By leveraging Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) architectures, this approach provides a robust solution for question duplication, enhancing the overall user experience on platforms like Stack Overflow.
The Challenge of Duplicate Detection in Large Forums
In online forums, the volume of user-generated content continues to grow, often resulting in repeated or duplicate questions. Identifying duplicate questions is crucial for efficient information retrieval and community engagement. Stack Overflow, a widely used programming Q&A platform, faces this issue daily, with millions of questions asked on similar topics.
- The Need for Accurate Question Similarity Models
-
- Question similarity requires understanding not only lexical similarities but also semantic nuances in user queries. Traditional keyword matching often falls short in identifying paraphrased or semantically equivalent questions. Faseeh and Jamil’s model tackles this by combining CNN and LSTM networks to analyze both local text patterns and long-term dependencies, capturing a more nuanced understanding of question similarity.
- Leveraging CNN and LSTM for Enhanced Performance
-
- CNNs excel in capturing localized patterns within the text, while LSTMs are designed for sequential data, allowing the model to retain contextual information. In this hybrid approach, CNN extracts features related to word positioning and patterns, and LSTM captures the sequence and context, resulting in a highly effective duplicate detection model.
- Dataset and Experimental Results
-
- The researchers used a dataset from Stack Overflow, comprising 416,860 questions. Each question pair was marked as duplicate or unique. Testing their model with a range of optimizers, activation functions, and embeddings, the CNN-LSTM hybrid model with the Nadam optimizer achieved an impressive accuracy of 0.74, outperforming traditional methods.
Benefits of the Hybrid CNN-LSTM Model
- Improved Detection Accuracy: By combining CNN and LSTM, the model effectively captures complex text relationships, yielding higher detection accuracy for duplicates.
- Applicability Beyond Stack Overflow: This method has potential applications across various Q&A platforms, where identifying and merging duplicate queries can streamline information sharing and enhance user satisfaction.
- Enhanced User Experience: With accurate duplicate detection, users can find existing answers faster, leading to a more efficient knowledge-sharing environment.
Conclusion:
This deep learning model for duplicate detection represents a significant advancement in natural language processing for online platforms. By merging CNN and LSTM networks, Faseeh and Jamil provide a robust framework to handle duplicate questions effectively, not only on Stack Overflow but potentially on any community-driven platform. This innovative approach sets the stage for further applications of deep learning in streamlining online content and improving user experience.
To explore the full study, visit IgMin Research or access the DOI: 10.61927/igmin135.
Tags:
Duplicate Question Detection, Deep Learning, Stack Overflow, CNN-LSTM Hybrid Model, Natural Language Processing, IgMin Research, Question Similarity
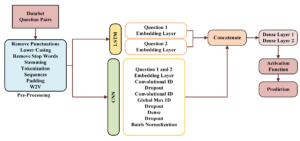
Figure: Proposed CNN and LSTM-based Approach.