
Enhancing Missing Values Imputation through Transformer-Based Predictive Modeling
Introduction
Data-driven analysis often faces a critical challenge—handling missing values in datasets. Traditional methods like zero, mean, and K-Nearest Neighbor (KNN) imputations, while commonly used, often fall short in capturing complex data patterns. This post explores an innovative transformer-based approach to missing value imputation, which leverages self-attention mechanisms to achieve superior accuracy, preserving the dataset’s integrity for more reliable analysis.
The Need for Advanced Imputation Techniques
Missing values in datasets can significantly compromise analytical outcomes. Conventional imputation methods tend to introduce bias, and discarding records with missing values leads to information loss. Recognizing these limitations, this study introduces a transformer-based model that adapts to complex patterns within the data. Unlike rule-based approaches, this model dynamically learns from data sequences to predict missing values, marking a shift towards a data-driven, adaptive solution.
For detailed insights, refer to the full text or access the study via DOI link(igmin140).
Methodology: A Step-by-Step Transformer-Based Process
The methodology begins by segmenting complete data for model training, with missing data points reserved for prediction. The process then involves:
- Data Preparation: Data sequences are labeled, and complete data points are segregated to enhance traceability.
- Model Training: The transformer model is trained on complete sequences, enabling it to learn intricate relationships within the data.
- Iterative Prediction: The trained model predicts missing values iteratively, integrating imputed values back into the dataset until all gaps are filled.
Validation and Comparative Analysis
To validate the model, the study compared its imputation accuracy against traditional methods like zero, mean, mode, and KNN imputations. An LSTM network further assessed the temporal coherence of the imputed values, with results indicating that the transformer model outperformed all other methods across diverse datasets, such as hourly, daily, and monthly data.
Key Results and Performance Metrics
The transformer model achieved exceptional R² scores across datasets:
- Hourly Data: R² score of 0.96, significantly surpassing KNN’s 0.765.
- Daily Data: R² score of 0.806, outperforming mean imputation by 0.25.
- Monthly Data: R² score of 0.796, marking a substantial improvement over traditional methods.
Figures in the document showcase a comparative analysis of the R² scores and error metrics (MAE, MSE, and RMSE), highlighting the transformer model’s consistent performance in preserving data relationships and capturing variability.
Applications and Future Directions
This transformer-based approach demonstrates promising potential in fields like healthcare, finance, and environmental monitoring, where data integrity is essential. However, the study also recognizes that further advancements, particularly in computational efficiency, are needed for scalability. Future research may explore integrating additional machine learning techniques to further enhance model robustness.
Conclusion
Transformer-based predictive modeling offers a powerful alternative for missing value imputation, pushing beyond traditional methods to deliver highly accurate and context-aware results. This study provides a foundation for future developments in data preprocessing and enhances the reliability of data-driven insights in complex datasets.
Tags:
Data Imputation, Transformer Model, Missing Values, Data Preprocessing, Predictive Modeling, Artificial Intelligence, Machine Learning, LSTM Validation.
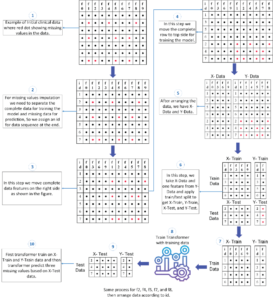
Figure 1: A detailed process of preparing data for the Transformer for missing values prediction.