Innovative Deep Learning Model for Semantic Segmentation of Natural and Medical Images
Introduction
Semantic segmentation is a key technology in the fields of computer vision and deep learning, driving advancements in autonomous driving and medical imaging. However, the challenge of accurately segmenting objects, especially in complex environments, remains significant. This blog post discusses a new deep learning model that combines Convolutional Neural Networks (CNN) with Holistically-Nested Edge Detection (HED) and Spatial Pyramid Pooling (SPP) to improve segmentation accuracy in both natural and medical images.
Enhancing Accuracy with CNN, HED, and SPP
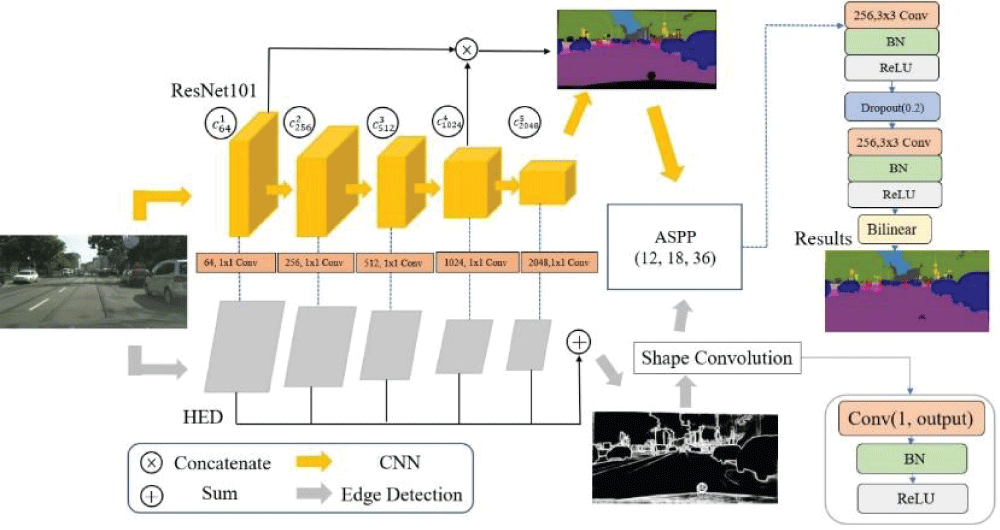
Traditional deep learning models like CNNs have shown great success in object detection. However, they often struggle to detect object edges with high precision. The newly proposed model addresses this limitation by incorporating HED, which improves the robustness of edge detection, and SPP, which allows for multi-scale feature extraction. This combination helps in detecting both large and small objects more accurately, as demonstrated by testing on the CityScapes dataset.
Applications in Real-Time Driving and Medical Imaging
Autonomous Driving: The model’s ability to accurately identify small objects on the road makes it valuable for enhancing safety in autonomous vehicles. By improving the precision of object edges, the model reduces the likelihood of detection errors that could lead to accidents.
Medical Imaging: In the field of medicine, precise segmentation is crucial for diagnosing conditions using imaging techniques like MRI and CT scans. The enhanced edge detection capabilities of this model enable better visualization of complex anatomical structures, assisting doctors in providing early and accurate diagnoses.
Key Achievements of the Model
- Improved Small Object Detection: The model achieves a Class mIoU of 77.51% for small objects and 89.95% for large objects, making it highly effective in diverse environments.
- Faster Training with Reduced Parameters: By using a deep ResNet for feature extraction and removing some computationally intensive operations, the model balances accuracy with training efficiency.
- Adaptable Architecture: The modular design allows for flexibility, making it suitable for various tasks in computer vision, from medical image segmentation to real-time object detection in autonomous systems.
Challenges and Future Directions
Despite its successes, the model faces challenges such as potential overfitting due to its complexity. The addition of dropout layers and multiple convolutional layers helps mitigate this, but further improvements could focus on simplifying the architecture without sacrificing accuracy. Future research may explore integrating this model with advanced AI techniques to further enhance real-time processing capabilities.
Conclusion
This new model for deep semantic segmentation represents a significant advancement in image analysis, offering improved accuracy for both natural and medical images. By addressing the limitations of traditional CNNs and enhancing edge detection through HED and SPP, it paves the way for more reliable applications in autonomous driving and healthcare. For a detailed look at the research, you can access the study here: Full Text, PDF, and DOI.
Tags: #SemanticSegmentation #DeepLearning #ComputerVision #MedicalImaging #CNN #EdgeDetection #AutonomousDriving #ImageProcessing #AIInMedicine #IgMinResearch