
Refining Material Property Forecasting via Optimized KNN Imputation and DNN Techniques
Optimizing Material Property Predictions: A Deep Dive into KNN Imputation and DNN Modeling
Data is the cornerstone of innovation in material science, enabling researchers to predict properties like strength, durability, and flexibility of materials critical for various applications. However, incomplete datasets remain a significant obstacle, potentially undermining the accuracy of predictions and the reliability of models. This blog explores a cutting-edge study on optimizing material property predictions by integrating an enhanced K-Nearest Neighbors (KNN) imputation method with Deep Neural Network (DNN) modeling.
The study, detailed in IGMIN Research Article #197, presents a robust framework for addressing missing data and highlights how advanced imputation techniques and deep learning can revolutionize predictive modeling in material science.
The Challenge of Missing Data in Material Science
Material science heavily relies on high-quality datasets for accurate predictions. Unfortunately, due to measurement errors, experimental limitations, or data unavailability, datasets often contain gaps. Missing data can lead to biased outcomes, reduced model efficiency, and unreliable predictions.
Common Solutions and Their Shortcomings
Traditional methods like mean or median imputation are simple to implement but fail to preserve the variability and complex relationships within data. These approaches often introduce significant bias, compromising the integrity of the predictions.
Advanced statistical methods such as Multiple Imputation by Chained Equations (MICE) offer better approximations by considering multivariate relationships. However, they can be computationally intensive and may not fully capture the intricate patterns present in material datasets.
Enhanced KNN Imputation: A Breakthrough
The enhanced KNN imputation method introduced in the study significantly improves data integrity and prediction accuracy. This method builds on the foundational KNN approach, which estimates missing values based on the ‘k’ nearest neighbors.
Key Features of Enhanced KNN
Hyperparameter Optimization: The method fine-tunes parameters such as the number of neighbors and distance metrics (e.g., Euclidean or Manhattan distances) through grid search. This ensures optimal performance tailored to the dataset’s characteristics.
Hybrid Techniques: Enhanced KNN combines clustering algorithms and iterative methods to improve handling of high-dimensional datasets, making it ideal for complex material science data.
Superior Performance: The optimized KNN achieved an R² score of 0.973, demonstrating a substantial improvement over traditional methods:
- Mean Imputation: 0.746
- MICE: 0.832
- Standard KNN: 0.929
Deep Neural Network (DNN) Modeling
Once missing data is imputed using enhanced KNN, the completed dataset is fed into a Deep Neural Network (DNN). DNNs are powerful tools for modeling complex, non-linear relationships in data, making them ideal for predicting intricate material properties like density, elasticity, and thermal conductivity.
DNN Training Process
- Preprocessing: Data is prepared to eliminate anomalies and ensure compatibility with the DNN architecture.
- Architecture Design: The neural network is constructed with multiple hidden layers and activation functions designed for continuous output.
- Training and Validation: The model is trained using backpropagation, with performance evaluated through metrics like Mean Squared Error (MSE) and R² scores.
Advantages of Combining DNN with KNN-Imputed Data
- Enhanced Predictions: Using KNN-imputed data as input improves the DNN’s ability to generalize and achieve higher accuracy.
- Preservation of Relationships: The enhanced imputation method maintains the dataset’s statistical properties, enabling the DNN to make reliable predictions.
Proposed Framework: A Comprehensive Workflow
The study outlines a meticulous framework combining enhanced KNN and DNN to optimize material property predictions:
Step 1: Data Imputation with Enhanced KNN
- Identify missing values and replace them with placeholders.
- Construct a distance matrix to locate the nearest neighbors.
- Optimize the number of neighbors and distance metrics using grid search.
- Impute missing values based on the weighted averages of neighbors.
Step 2: Training DNN for Prediction
- Use the completed dataset to train the DNN, splitting the data into training and testing sets.
- Employ activation functions and hidden layers suited for continuous data.
- Evaluate the model’s performance using metrics like MSE and R².
Step 3: Comparative Analysis
- Compare the results of enhanced KNN imputation against traditional methods (mean, MICE, and standard KNN).
- Analyze the predictive performance of the DNN model using the imputed datasets.
Results and Insights
The study demonstrates the efficacy of the proposed framework, with key findings including:
Improved R² Scores: The enhanced KNN imputation method delivered the highest R² score (0.973), surpassing traditional methods by significant margins.
Preservation of Data Integrity: The optimized imputation technique maintained the statistical properties of the dataset, ensuring reliable inputs for the DNN.
Scalability: While computationally demanding, the method proved robust across various datasets, highlighting its potential for widespread application.
Applications and Implications
Industrial Applications
- Aerospace and Automotive: Accurate predictions of material properties like strength and thermal resistance can improve the design of lightweight, durable components.
- Construction and Manufacturing: Predictive models can guide the development of advanced composites and alloys.
Research Advancements
Reliable data enables researchers to focus on experimental innovations rather than compensating for missing values, accelerating breakthroughs in material science.
Education and Training
Integrating machine learning frameworks like KNN and DNN into academic curricula can equip students with the skills needed to tackle real-world challenges in engineering and material science.
Challenges and Future Directions
Current Limitations
- Computational Costs: Optimized KNN and DNN require significant resources for large datasets.
- Generalizability: Further validation is needed across diverse datasets to confirm the method’s robustness.
Opportunities for Innovation
- Hybrid Models: Combining KNN with other machine learning algorithms, such as decision trees or random forests, could further enhance imputation accuracy.
- Real-Time Applications: Developing lightweight algorithms for real-time predictions can expand the utility of these methods in industrial settings.
Conclusion
The integration of enhanced KNN imputation and DNN modeling represents a transformative approach to addressing missing data challenges in material science. By preserving data integrity and improving prediction accuracy, this framework not only enhances research outcomes but also drives industrial innovation.
For practitioners and researchers, adopting these advanced methodologies offers a pathway to more reliable and precise material property predictions, paving the way for groundbreaking advancements in engineering and design.
Tags
- Material Science
- Machine Learning
- Data Imputation
- KNN Imputation
- Deep Neural Networks
- Predictive Modeling
- Advanced Material Design
- AI in Engineering
- DNN Applications
- Data Science in Material Science
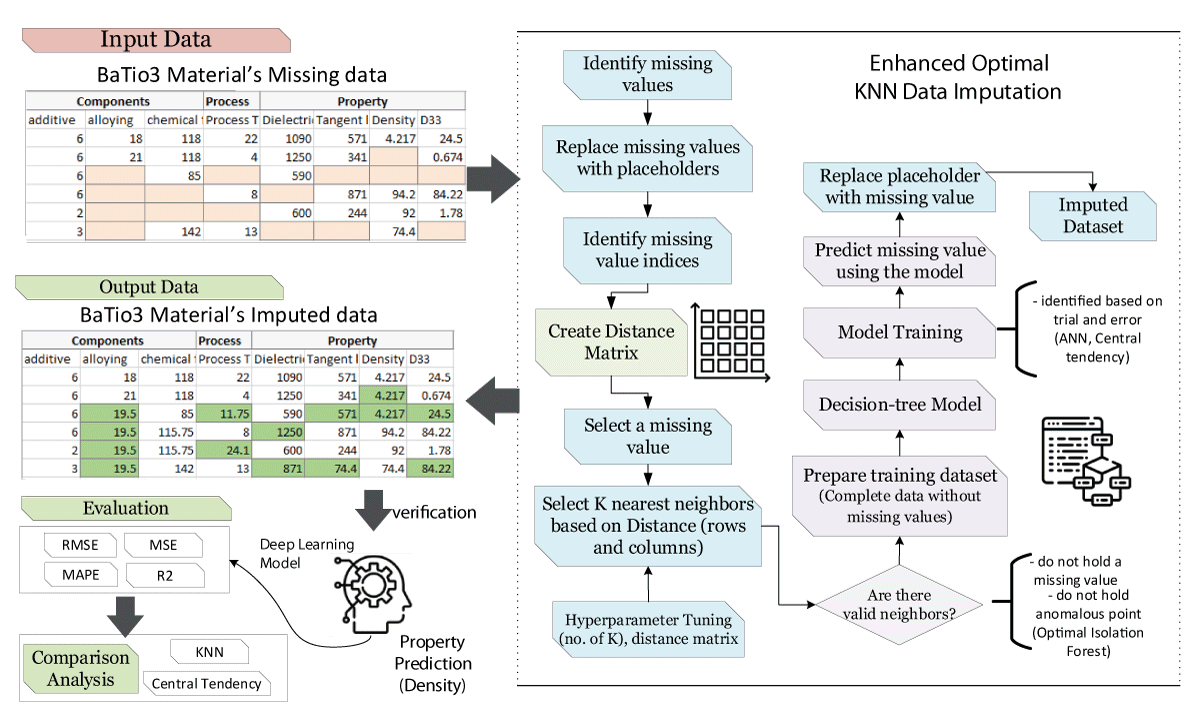
A detailed Framework of the proposed methodology for missing values imputation.